🚘 Novel Deep Learning Architectures for 3D LiDAR Recognition
[1] 3D Adaptive Structural Convolution Network for Domain-Invariant Point Cloud Recognition
Younggun Kim and Soomok Lee*
🎉 Asian Conference on Computer Vision (ACCV), 2024. [BK21(Brain Korea) Distinguished Conference Paper List]
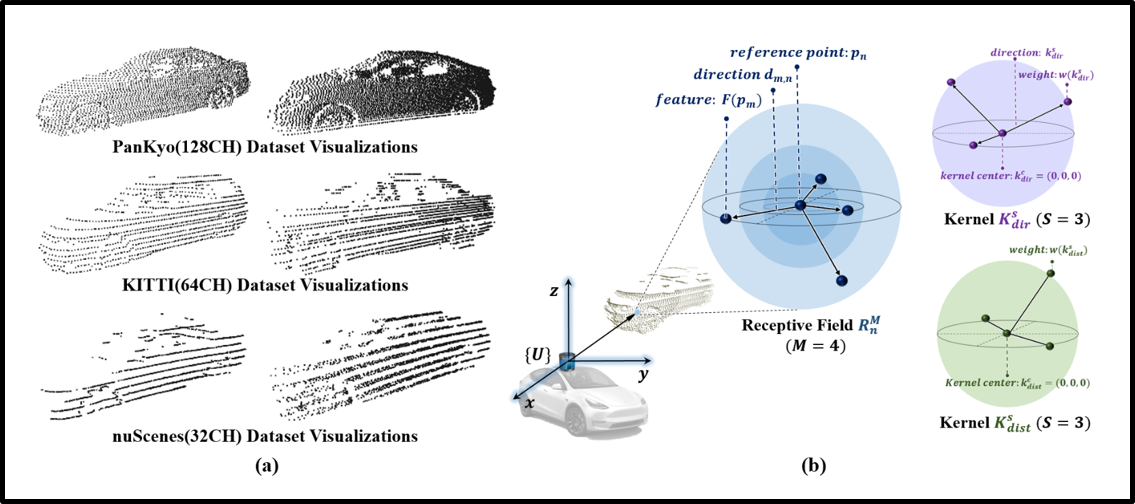
Motivation: LiDAR is one of the crucial sensors for autonomous vehicles (AVs), offering accurate 3D spatial information essential for object recognition and safe navigation. However, the quality of LiDAR point clouds varies significantly with the number of channels (e.g., 32CH, 64CH, 128CH), and high-channel sensors are often too expensive for wide deployment. This creates a challenge, as deep learning models trained on high-resolution data often underperform when applied to lower-resolution inputs. Thus, it is critical to develop recognition models that are robust to LiDAR channel variations.
Methodology: We developed 3D-ASCN that recognizes objects using 3D point cloud data from LiDAR sensors. To address the challenges caused by variations in LiDAR sensor configurations, our model is designed to maintain reliable performance even when the quality or resolution of LiDAR data changes. Specifically, we introduce a distance-based kernel and a direction-based kernel that learn the structural feature representations of objects from point clouds. These kernels enable the model to focus on the intrinsic geometry of objects rather than the density of the point cloud itself, allowing for robust classification and object detection across different LiDAR resolutions.
Impact: The proposed 3D-ASCN can contribute to the real-world deployment of AVs by enabling reliable object recognition regardless of the LiDAR sensor used. By overcoming performance degradation caused by LiDAR channel shifts, our approach reduces hardware dependency and cost, allowing AV systems to be both scalable and economically feasible.
[2] Multi-view Structural Convolution Network for Domain-Invariant Point Cloud Recognition of Autonomous Vehicles
Younggun Kim, Mohamed Abdel-Aty, Beomsik Cho, Seonghoon Ryoo, and Soomok Lee*
This work has been submitted to IEEE Transactions on Intelligent Vehicles (T-IV). [Impact Factor: 14.3, JCR Quartiles: Q1, Conditionally Accepted]
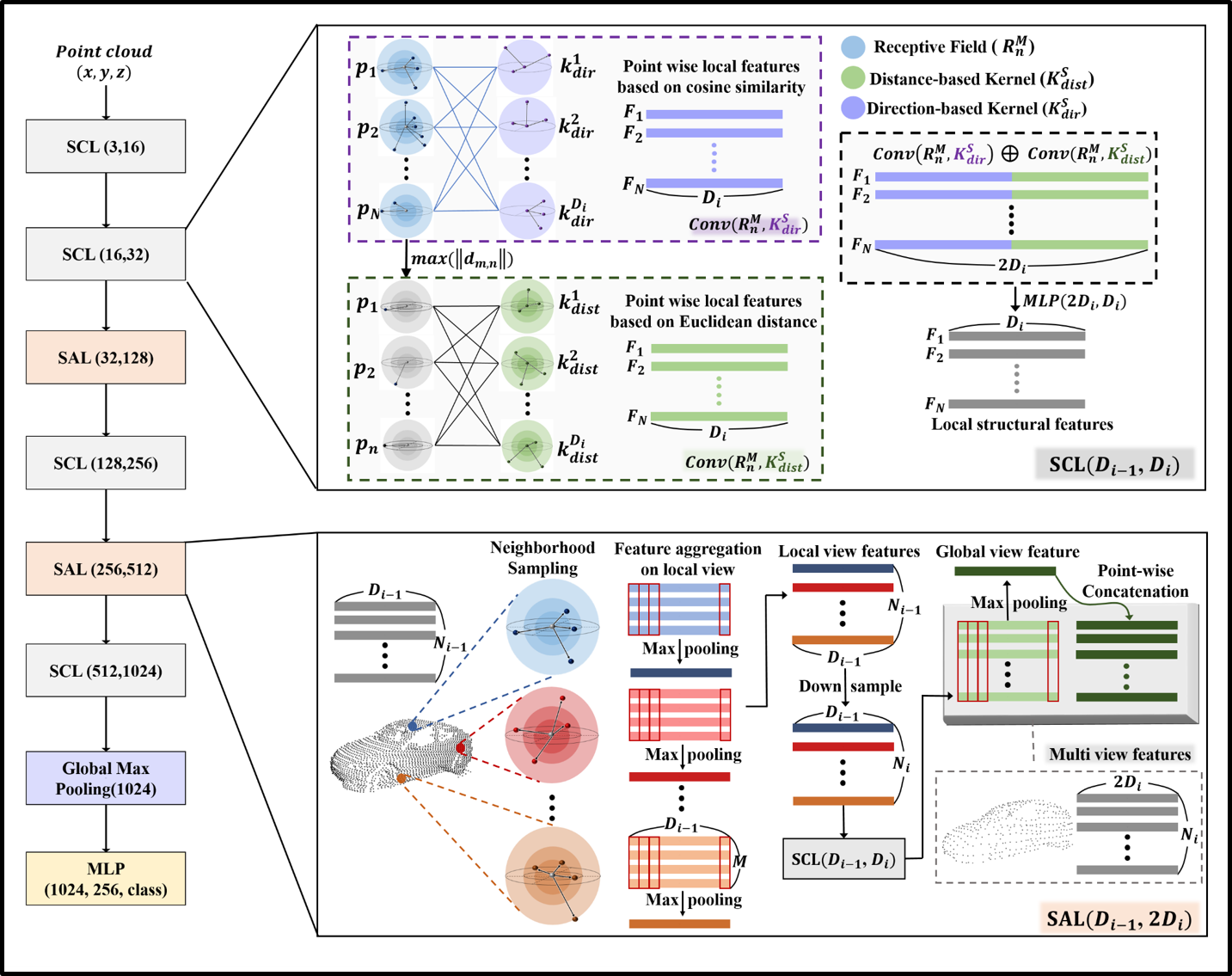
- We developed MSCN, an improved version of the previously proposed 3D-ASCN model, which robustly recognizes objects from point clouds under both LiDAR channel variations and domain shifts between simulation and real-world environments.
- While 3D-ASCN focuses on local structural features centered around each point, MSCN extends this by capturing both local and global structural features, leading to improved recognition performance and robustness to domain shifts.
- To evaluate the model’s recognition ability under simulation-to-real-world (Sim-to-Real) domain shifts, we developed a synthetic point cloud dataset. This dataset enabled rigorous testing of sim-to-real generalization, validating MSCN’s robustness in diverse deployment scenarios.
- Impact: MSCN enables cost-effective deployment of AV systems by maintaining strong recognition performance across both varying LiDAR sensor configurations (e.g., low-cost vs. high-resolution sensors) and domain shifts between synthetic and real-world data, addressing key challenges in both sensor variability and data availability.